CAT#:JW-1-1720
低温运输,-20℃保存
产品及特点
本产品为pcDNA6.2-GWEmGFp-miR质粒DNA,为Gateway系统载体,具有CMV启动子,采用多克隆位点限制性内切酶进行克隆,具有大观霉素抗性;可用于Blasticidin的筛选标记,其图谱如下: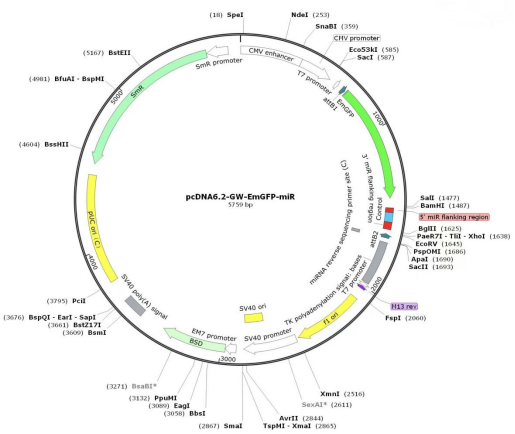
规格及成分
本产品使用塑料袋包装
成分 编号 规格 包装
pcDNA6.2-GWEmGFp-miR质粒DNA溶液 1-1720 2 mg 0.5 mL本色管
使用手册 1-1720sc 1份 无
运输及保存
低温运输,-20℃保存,有效期两年
使用方法
取1µL本产品按实验室常用的SOP进行大肠杆菌转化。
DNA序列
11 GTTGACATTG ATTATTGACT AGTTATTAAT AGTAATCAAT TACGGGGTCA 50
151 TTAGTTCATA GCCCATATAT GGAGTTCCGC GTTACATAAC TTACGGTAAA 100
101 TGGCCCGCCT GGCTGACCGC CCAACGACCC CCGCCCATTG ACGTCAATAA 150
151 TGACGTATGT TCCCATAGTA ACGCCAATAG GGACTTTCCA TTGACGTCAA 200
201 TGGGTGGAGT ATTTACGGTA AACTGCCCAC TTGGCAGTAC ATCAAGTGTA 250
251 TCATATGCCA AGTACGCCCC CTATTGACGT CAATGACGGT AAATGGCCCG 300
301 CCTGGCATTA TGCCCAGTAC ATGACCTTAT GGGACTTTCC TACTTGGCAG 350
351 TACATCTACG TATTAGTCAT CGCTATTACC ATGGTGATGC GGTTTTGGCA 400
401 GTACATCAAT GGGCGTGGAT AGCGGTTTGA CTCACGGGGA TTTCCAAGTC 450
451 TCCACCCCAT TGACGTCAAT GGGAGTTTGT TTTGGCACCA AAATCAACGG 500
501 GACTTTCCAA AATGTCGTAA CAACTCCGCC CCATTGACGC AAATGGGCGG 550
551 TAGGCGTGTA CGGTGGGAGG TCTATATAAG CAGAGCTCTC TGGCTAACTA 600
601 GAGAACCCAC TGCTTACTGG CTTATCGAAA TTAATACGAC TCACTATAGG 650
651 GAGTCCCAAG CTGGCTAGTT AAGCTATCAA CAAGTTTGTA CAAAAAAGCA 700
701 GGCTTTAAAA CCATGGTGAG CAAGGGCGAG GAGCTGTTCA CCGGGGTGGT 750
751 GCCCATCCTG GTCGAGCTGG ACGGCGACGT AAACGGCCAC AAGTTCAGCG 800
801 TGTCCGGCGA GGGCGAGGGC GATGCCACCT ACGGCAAGCT GACCCTGAAG 850
851 TTCATCTGCA CCACCGGCAA GCTGCCCGTG CCCTGGCCCA CCCTCGTGAC 900
901 CACCTTCACC TACGGCGTGC AGTGCTTCGC CCGCTACCCC GACCACATGA 950
1951 CGCACCATCT TCTTCAAGGA CGACGGCAAC TACAAGACCC GCGCCGAGGT 1000
1001 GAAGTTCGAG GGCGACACCC TGGTGAACCG CATCGAGCTG AAGGGCATCG 1050
1051 ACTTCAAGGA GGACGGCAAC ATCCTGGGGC ACAAGCTGGA GTACAACTAC 1100
1101 AACAGCCACA AGGTCTATAT CACCGCCGAC AAGCAGAAGA ACGGCATCAA 1150
1151 GGTGAACTTC AAGACCCGCC ACAACATCGA GGACGGCAGC GTGCAGCTCG 1200
1201 CCGACCACTA CCAGCAGAAC ACCCCCATCG GCGACGGCCC CGTGCTGCTG 1250
1251 CCCGACAACC ACTACCTGAG CACCCAGTCC GCCCTGAGCA AAGACCCCAA 1300
1301 CGAGAAGCGC GATCACATGG TCCTGCTGGA GTTCGTGACC GCCGCCGGGA 1350
1351 TCACTCTCGG CATGGACGAG CTGTACAAGT AAGCTAAGCA CTTCGTGGCC 1400
1401 GTCGATCGTT TAAAGGGAGG TAGTGAGTCG ACCAGTGGAT CCTGGAGGCT 1450
1451 TGCTGAAGGC TGTATGCTGT GTCAGTTTGT CAAATACCCC GTTTTGGCCA 1500
1501 CTGACTGACG GGGTATTACA AACTGACACA GGACACAAGG CCTGTTACTA 1550
1551 GCACTCACAT GGAACAAATG GCCCAGATCT GGCCGCACTC GAGATATCTA 1600
1601 GACCCAGCTT TCTTGTACAA AGTGGTTGAT CTAGAGGGCC CGCGGTTCGC 1650
1651 TGATGGGGGA GGCTAACTGA AACACGGAAG GAGACAATAC CGGAAGGAAC 1700
1701 CCGCGCTATG ACGGCAATAA AAAGACAGAA TAAAACGCAC GGGTGTTGGG 1750
1751 TCGTTTGTTC ATAAACGCGG GGTTCGGTCC CAGGGCTGGC ACTCTGTCGA 1800
1801 TACCCCACCG TGACCCCATT GGGGCCAATA CGCCCGCGTT TCTTCCTTTT 1850
1851 CCCCACCCCA CCCCCCAAGT TCGGGTGAAG GCCCAGGGCT CGCAGCCAAC 1900
1901 GTCGGGGCGG CAGGCCCTGC CATAGCATCC CCTATAGTGA GTCGTATTAC 1950
1951 ATGGTCATAG CTGTTTCCTG GCAGCTCTGG CCCGTGTCTC AAAATCTCTG 2000
2001 ATGGATCTGC GCAGCTGGGG CTCTAGGGGG TATCCCCACG CGCCCTGTAG 2050
2051 CGGCGCATTA AGCGCGGCGG GTGTGGTGGT TACGCGCAGC GTGACCGCTA 2100
2101 CACTTGCCAG CGCCCTAGCG CCCGCTCCTT TCGCTTTCTT CCCTTCCTTT 2150
2151 CTCGCCACGT TCGCCGGCTT TCCCCGTCAA GCTCTAAATC GGGGGCTCCC 2200
2201 TTTAGGGTTC CGATTTAGTG CTTTACGGCA CCTCGACCCC AAAAAACTTG 2250
2251 ATTAGGGTGA TGGTTCACGT AGTGGGCCAT CGCCCTGATA GACGGTTTTT 2300
2301 CGCCCTTTGA CGTTGGAGTC CACGTTCTTT AATAGTGGAC TCTTGTTCCA 2350
2351 AACTGGAACA ACACTCAACC CTATCTCGGT CTATTCTTTT GATTTATAAG 2400
2401 GGATTTTGCC GATTTCGGCC TATTGGTTAA AAAATGAGCT GATTTAACAA 2450
2451 AAATTTAACG CGAATTAATT CTGTGGAATG TGTGTCAGTT AGGGTGTGGA 2500
2501 AAGTCCCCAG GCTCCCCAGC AGGCAGAAGT ATGCAAAGCA TGCATCTCAA 2550
2551 TTAGTCAGCA ACCAGGTGTG GAAAGTCCCC AGGCTCCCCA GCAGGCAGAA 2600
2601 GTATGCAAAG CATGCATCTC AATTAGTCAG CAACCATAGT CCCGCCCCTA 2650
2651 ACTCCGCCCA TCCCGCCCCT AACTCCGCCC AGTTCCGCCC ATTCTCCGCC 2700
2701 CCATGGCTGA CTAATTTTTT TTATTTATGC AGAGGCCGAG GCCGCCTCTG 2750
2751 CCTCTGAGCT ATTCCAGAAG TAGTGAGGAG GCTTTTTTGG AGGCCTAGGC 2800
2801 TTTTGCAAAA AGCTCCCGGG AGCTTGTATA TCCATTTTCG GATCTGATCA 2850
2851 GCACGTGTTG ACAATTAATC ATCGGCATAG TATATCGGCA TAGTATAATA 2900
2901 CGACAAGGTG AGGAACTAAA CCATGGCCAA GCCTTTGTCT CAAGAAGAAT 2950
2951 CCACCCTCAT TGAAAGAGCA ACGGCTACAA TCAACAGCAT CCCCATCTCT 3000
3001 GAAGACTACA GCGTCGCCAG CGCAGCTCTC TCTAGCGACG GCCGCATCTT 3050
3051 CACTGGTGTC AATGTATATC ATTTTACTGG GGGACCTTGT GCAGAACTCG 3100
3101 TGGTGCTGGG CACTGCTGCT GCTGCGGCAG CTGGCAACCT GACTTGTATC 3150
3151 GTCGCGATCG GAAATGAGAA CAGGGGCATC TTGAGCCCCT GCGGACGGTG 3200
3201 CCGACAGGTG CTTCTCGATC TGCATCCTGG GATCAAAGCC ATAGTGAAGG 3250
3251 ACAGTGATGG ACAGCCGACG GCAGTTGGGA TTCGTGAATT GCTGCCCTCT 3300
3301 GGTTATGTGT GGGAGGGCTA AGCACTTCGT GGCCGAGGAG CAGGACTGAC 3350
3351 ACGTGCTACG AGATTTCGAT TCCACCGCCG CCTTCTATGA AAGGTTGGGC 3400
3401 TTCGGAATCG TTTTCCGGGA CGCCGGCTGG ATGATCCTCC AGCGCGGGGA 3450
3451 TCTCATGCTG GAGTTCTTCG CCCACCCCAA CTTGTTTATT GCAGCTTATA 3500
3501 ATGGTTACAA ATAAAGCAAT AGCATCACAA ATTTCACAAA TAAAGCATTT 3550
3551 TTTTCACTGC ATTCTAGTTG TGGTTTGTCC AAACTCATCA ATGTATCTTA 3600
3601 TCATGTCTGT ATACCGTCGC TCTTCCGCTG CTTCCTCGCT CACTGACTCG 3650
3651 CTGCGCTCGG TCGTTCGGCT GCGGCGAGCG GTATCAGCTC ACTCAAAGGC 3700
3701 GGTAATACGG TTATCCACAG AATCAGGGGA TAACGCAGGA AAGAACATGT 3750
3751 GAGCAAAAGG CCAGCAAAAG GCCAGGAACC GTAAAAAGGC CGCGTTGCTG 3800
3801 GCGTTTTTCC ATAGGCTCCG CCCCCCTGAC GAGCATCACA AAAATCGACG 3850
3851 CTCAAGTCAG AGGTGGCGAA ACCCGACAGG ACTATAAAGA TACCAGGCGT 3900
3901 TTCCCCCTGG AAGCTCCCTC GTGCGCTCTC CTGTTCCGAC CCTGCCGCTT 3950
3951 ACCGGATACC TGTCCGCCTT TCTCCCTTCG GGAAGCGTGG CGCTTTCTCA 4000
4001 TAGCTCACGC TGTAGGTATC TCAGTTCGGT GTAGGTCGTT CGCTCCAAGC 4050
4051 TGGGCTGTGT GCACGAACCC CCCGTTCAGC CCGACCGCTG CGCCTTATCC 4100
4101 GGTAACTATC GTCTTGAGTC CAACCCGGTA AGACACGACT TATCGCCACT 4150
4151 GGCAGCAGCC ACTGGTAACA GGATTAGCAG AGCGAGGTAT GTAGGCGGTG 4200
4201 CTACAGAGTT CTTGAAGTGG TGGCCTAACT ACGGCTACAC TAGAAGAACA 4250
4251 GTATTTGGTA TCTGCGCTCT GCTGAAGCCA GTTACCTTCG GAAAAAGAGT 4300
4301 TGGTAGCTCT TGATCCGGCA AACAAACCAC CGCTGGTAGC GGTGGTTTTT 4350
4351 TTGTTTGCAA GCAGCAGATT ACGCGCAGAA AAAAAGGATC TCAAGAAGAT 4400
4401 CCTTTGATCT TTTCTACGGG GTCTGACGCT CAGTGGAACG ACGCGTAACT 4450
4451 CACGTTAAGG GATTTTGGTC ATGGGTGGCT CGACGAGGGT TATTTGCCGA 4500
4501 CTACCTTGGT GATCTCGCCT TTCACGTAGT GGACAAATTC TTCCAACTGA 4550
4551 TCTGCGCGCG AGGCCAAGCG ATCTTCTTCT TGTCCAAGAT AAGCCTGTCT 4600
4601 AGCTTCAAGT ATGACGGGCT GATACTGGGC CGGCAGGCGC TCCATTGCCC 4650
4651 AGTCGGCAGC GACATCCTTC GGCGCGATTT TGCCGGTTAC TGCGCTGTAC 4700
4701 CAAATGCGGG ACAACGTAAG CACTACATTT CGCTCATCGC CAGCCCAGTC 4750
4751 GGGCGGCGAG TTCCATAGCG TTAAGGTTTC ATTTAGCGCC TCAAATAGAT 4800
4801 CCTGTTCAGG AACCGGATCA AAGAGTTCCT CCGCCGCTGG ACCTACCAAG 4850
4851 GCAACGCTAT GTTCTCTTGC TTTTGTCAGC AAGATAGCCA GATCAATGTC 4900
4901 GATCGTGGCT GGCTCGAAGA TACCTGCAAG AATGTCATTG CGCTGCCATT 4950
4951 CTCCAAATTG CAGTTCGCGC TTAGCTGGAT AACGCCACGG AATGATGTCG 5000
5001 TCGTGCACAA CAATGGTGAC TTCTACAGCG CGGAGAATCT CGCTCTCTCC 5050
5051 AGGGGAAGCC GAAGTTTCCA AAAGGTCGTT GATCAAAGCT CGCCGCGTTG 5100
5101 TTTCATCAAG CCTTACGGTC ACCGTAACCA GCAAATCAAT ATCACTGTGT 5150
5151 GGCTTCAGGC CGCCATCCAC TGCGGAGCCG TACAAATGTA CGGCCAGCAA 5200
5201 CGTCGGTTCG AGATGGCGCT CGATGACGCC AACTACCTCT GATAGTTGAG 5250
5251 TCGATACTTC GGCGATCACC GCTTCCCTCA TAATGTTTAA CTTTGTTTTA 5300
5301 GGGCGACTGC CCTGCTGCGT AACATCGTTG CTGCTCCATA ACATCAAACA 5350
5351 TCGACCCACG GCGTAACGCG CTTGCTGCTT GGATGCCCGA GGCATAGACT 5400
5401 GTACCCCAAA AAAACAGTCA TAACAAGCCA TGAAAACCGC CACTGCGCCG 5450
5451 TTACCACCGC TGCGTTCGGT CAAGGTTCTG GACCAGTTGC GTGAGCGCAT 5500
5501 ACGCTACTTG CATTACAGCT TACGAACCGA ACAGGCTTAT GTCCACTGGG 5550
5551 TTCGTGCCTT CATCCGTTTC CACGGTGTGC GTCACCCGGC AACCTTGGGT 5600
5601 AGCAGCGAAG TCGAGGCATT TCTGTCCTGG CTGGTCTAGA ATTGCATGAA 5650
5701 GAATCTGCTT AGGGTTAGGC GTTTTGCGCT GCTTCGCGAT GTACGGGCCA 5750
5751 GATATACGC 5759TTAGGC GTTTTGCGCT GCTTCGCGAT GTACGGGCCA 55800
关联产品
大肠杆菌DH5a感受态细胞
ELISA试剂盒
人ELISA试剂盒| 大鼠ELISA试剂盒| 小鼠ELISA试剂盒| 牛ELISA试剂盒| 猪ELISA试剂盒| 鸡ELISA试剂盒| 犬ELISA试剂盒| 猫ELISA试剂盒| 马ELISA试剂盒| 植物ELISA试剂盒| 山羊ELISA试剂盒| 绵羊ELISA试剂盒| 鸭ELISA试剂盒| 兔ELISA试剂盒| 鱼ELISA试剂盒| 豚鼠ELISA试剂盒| 鹅ELISA试剂盒| 药物残留ELISA试剂盒| 兽药残留快速检测卡| 毒素类ELISA试剂盒| 其他ELISA试剂盒| Human ELISA Kit| Rat ELISA Kit| Mouse ELISA Kit| Procine ELISA Kit| Rabbit ELISA Kit| Guinea ELISA Kit| Chicken ELISA Kit| Sheep ELISA Kit| Canine ELISA Kit| 其它ELISA试剂盒|
高敏ELISA试剂盒
高敏人Elisa试剂盒| 高敏小鼠Elisa试剂盒| 高敏大鼠Elisa试剂盒| 高敏豚鼠Elisa试剂盒| 高敏裸鼠Elisa试剂盒| 高敏仓鼠Elisa试剂盒| 高敏沙鼠Elisa试剂盒| 高敏鸭Elisa试剂盒| 高敏鹅Elisa试剂盒| 高敏猴Elisa试剂盒| 高敏兔Elisa试剂盒| 高敏马Elisa试剂盒| 高敏绵羊Elisa试剂盒| 高敏山羊Elisa试剂盒| 高敏犬Elisa试剂盒| 高敏牛Elisa试剂盒| 高敏鱼Elisa试剂盒|
技术服务
微量法检测系列| 细胞生物学| 分子生物学| 物质分析| 病理学| 免疫学| 病毒包装| 动物造模| 蛋白表达| 抗体制备| 文库构建和筛选| RACE实验| 杂交实验| HPLC法检测项目| 气相色谱法检测项目|
染色试剂&糖类
染色液| 固定液| 染料| 褐藻寡糖系列| 壳寡糖系列| 琼胶寡糖系列| 卡拉胶寡糖系列| 木寡糖系列| 棉籽半乳寡糖系列| 不饱和硫酸软骨素二糖系列| 透明质酸寡糖系列| 麦芽寡糖系列| 海洋寡糖原料类|
荧光定量比色法试剂盒
细胞技术类产品| 生化试剂盒| 分子技术类产品| 蛋白化学技术类产品| 免疫抗体技术类产品| 医学技术类产品| 病理技术类产品| 生物化学技术类产品| 模式生物技术类产品| 微生物技术类产品| 植物技术类产品| 载体技术类产品| 毒理技术类产品| 营养技术类产品| 平台技术类产品| 其他相关产品|
生化试剂
蛋白质类| 氨基酸&多肽&蛋白质| 抗生素(生化试剂)| 酶&辅酶&抑制剂| 动植物激素| 碳水化合物及衍生物| 色素类| 维生素| 分离材料及耗材| 表面活性剂| 缓冲溶剂| 其他化学试剂| 碱基&核酸及其衍生物| 酸&盐&胺| 常规生化试剂|
细胞生物学
细胞生长因子| 细胞辅助试剂| 细胞培养| 细胞检测试剂| 细胞系(株)| 细胞分离与消化| 细胞染色与探针| 细胞转染| 鲎试剂| 免疫细胞及干细胞| 其他原代细胞| 小鼠原代细胞| 大鼠原代细胞| 人源原代细胞| 其他细胞系| 小鼠细胞系| 大鼠细胞系| 人源细胞系|
分析对照品、标准品
农药标准物质| 天然药物系列单体| 英国LGC标准品| 美国药典标准品| 中检所标准品| 中药对照品| 对照药材| 标准溶液| 进口标准品| 分析对照品| 衍生化试剂| 离子对试剂|





