CAT#:1-282
低温运输,-20℃保存
产品及特点
本产品为pAAV-IRES-hrGFP质粒DNA溶液。pAAV-IRES-hrGFP质粒DNA是具有CMV启动子、pUC复制子和PolyA转录终止信号的腺病毒包装载体。pAAV-IRES-hrGFP质粒DNA携带hrGFP基因(人源化绿色荧光蛋白基因,Humanized Renilla reniformis Green Fluorescent Protein Gene),用户可根据实验需求将外源DNA插入hrGFP结构基因上游进行共表达实验。本质粒携带Amp抗性基因。其图谱如下: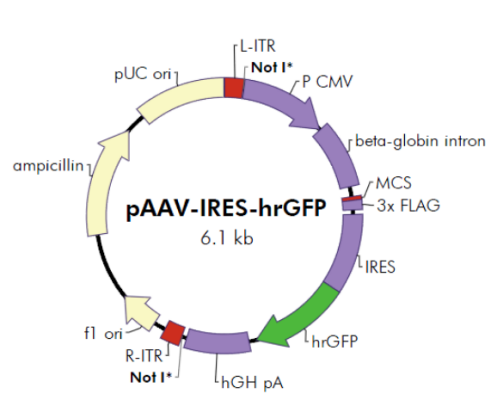
规格及成分
本产品使用塑料袋包装
成分 编号 规格 包装
pAAV-IRES-hrGFP质粒
DNA溶液,100 ng/μL 1-282 20 μL 0.5 mL本色管
使用手册 1-282sc 1 份 无
运输及保存
低温运输,-20℃保存,有效期两年。
使用方法
pAAV-IRES-hrGFP质粒DNA溶液可以直接用于腺病毒包装实验。也可以取少量,按常规方法进行细菌转化,制备更多的质粒DNA进行各种后续实验。
DNA序列
11 1 CCTGCAGGCA GCTGCGCGCT CGCTCGCTCA CTGAGGCCGC CCGGGCAAAG
151 CCCGGGCGTC GGGCGACCTT TGGTCGCCCG GCCTCAGTGA GCGAGCGAGC
101 GCGCAGAGAG GGAGTGGCCA ACTCCATCAC TAGGGGTTCC TGCGGCCGCA
151 CGCGTGGAGC TAGTTATTAA TAGTAATCAA TTACGGGGTC ATTAGTTCAT
201 AGCCCATATA TGGAGTTCCG CGTTACATAA CTTACGGTAA ATGGCCCGCC
251 TGGCTGACCG CCCAACGACC CCCGCCCATT GACGTCAATA ATGACGTATG
301 TTCCCATAGT AACGTCAATA GGGACTTTCC ATTGACGTCA ATGGGTGGAG
351 TATTTACGGT AAACTGCCCA CTTGGCAGTA CATCAAGTGT ATCATATGCC
401 AAGTACGCCC CCTATTGACG TCAATGACGG TAAATGGCCC GCCTGGCATT
451 ATGCCCAGTA CATGACCTTA TGGGACTTTC CTACTTGGCA GTACATCTAC
501 GTATTAGTCA TCGCTATTAC CATGGTGATG CGGTTTTGGC AGTACATCAA
551 TGGGCGTGGA TAGCGGTTTG ACTCACGGGG ATTTCCAAGT CTCCACCCCA
601 TTGACGTCAAT GGGAGTTTGT TTTGCACCA AAATCAACGG GACTTTCCAA
651 AATGTCGTAA CAACTCCGCC CCATTGACGC AAATGGGCGG TAGGCGTGTA
701 CGGTGGGAGG TCTATATAAG CAGAGCTCGT TTAGTGAACC GTCAGATCGC
751 CTGGAGACGC CATCCACGCT GTTTTGACCT CCATAGAAGA CACCGGGACC
801 GATCCAGCCT CCGCGGATTC GAATCCCGGC CGGGAACGGT GCATTGGAAC
851 GCGGATTCCC CGTGCCAAGA GTGACGTAAG TACCGCCTAT AGAGTCTATA
901 GGCCCACAAA AAATGCTTTC TTCTTTTAAT ATACTTTTTT GTTTATCTTA
951 TTTCTAATAC TTTCCCTAAT CTCTTTCTTT CAGGGCAATA ATGATACAAT
1001 GTATCATGCC TCTTTGCACC ATTCTAAAGA ATAACAGTGA TAATTTCTGG
1051 GTTAAGGCAA TAGCAATATT TCTGCATATA AATATTTCTG CATATAAATT
1101 GTAACTGATG TAAGAGGTTT CATATTGCTA ATAGCAGCTA CAATCCAGCT
1151 ACCATTCTGC TTTTATTTTA TGGTTGGGAT AAGGCTGGAT TATTCTGAGT
1201 CCAAGCTAGG CCCTTTTGCT AATCATGTTC ATACCTCTTA TCTTCCTCCC
1251 ACAGCTCCTG GGCAACGTGC TGGTCTGTGT GCTGGCCCAT CACTTTGGCA
1301 AAGAATTGGG ATTCGAACAT CGATAATTAA CCCTCACTAA AGGGAACAAA
1351 AGCTGGAGCT CCACCGCGGT GGCGGCCGCT CTAGCCCGGG CGGATCCGAA
1401 TTCGCATGCG TCGACTCGAG GACTACAAGG ATGACGATGA CAAGGATTAC
1451 AAAGACGACG ATGATAAGGA CTATAAGGAT GATGACGACA AATAATAGCA
1501 ATTCCTCGAC GACTGCATAG GGTTACCCCC CTCTCCCTCC CCCCCCCCTA
1551 ACGTTACTGG CCGAAGCCGC TTGGAATAAG GCCGGTGTGC GTTTGTCTAT
1601 ATGTTATTTT CCACCATATT GCCGTCTTTT GGCAATGTGA GGGCCCGGAA
1651 ACCTGGCCCT GTCTTCTTGAC GAGCATTCC TAGGGGTCTT TCCCCTCTCG
1701 CCAAAGGAAT GCAAGGTCTG TTGAATGTCG TGAAGGAAGC AGTTCCTCTG
1751 GAAGCTTCTT GAAGACAAAC AACGTCTGTA GCGACCCTTT GCAGGCAGCG
1801 GAACCCCCCA CCTGGCGACA GGTGCCTCTG CGGCCAAAAG CCACGTGTAT
1851 AAGATACACC TGCAAAGGCG GCACAACCCC AGTGCCACGT TGTGAGTTGG
1901 ATAGTTGTGG AAAGAGTCAA ATGGCTCTCC TCAAGCGTAT TCAACAAGGG
1951 GCTGAAGGAT GCCCAGAAGG TACCCCATTG TATGGGATCT GATCTGGGGC
2001 CTCGGTGCAC ATGCTTTACA TGTGTTTAGT CGAGGTTAAA AAACGTCTAG
2051 GCCCCCCGAA CCACGGGGAC GTGGTTTTCC TTTGAAAAAC ACGATGATAA
2101 TGGCCACAAC CATGGTGAGC AAGCAGATCC TGAAGAACAC CGGCCTGCAG
2151 GAGATCATGA GCTTCAAGGT GAACCTGGAG GGCGTGGTGA ACAACCACGT
2201 GTTCACCATG GAGGGCTGCG GCAAGGGCAA CATCCTGTTC GGCAACCAGC
2251 TGGTGCAGAT CCGCGTGACC AAGGGCGCCC CCCTGCCCTT CGCCTTCGAC
2301 ATCCTGAGCC CCGCCTTCCA GTACGGCAAC CGCACCTTCA CCAAGTACCC
2351 CGAGGACATC AGCGACTTCT TCATCCAGAG CTTCCCCGCC GGCTTCGTGT
2401 ACGAGCGCAC CCTGCGCTAC GAGGACGGCG GCCTGGTGGA GATCCGCAGC
2451 GACATCAACC TGATCGAGGA GATGTTCGTG TACCGCGTGG AGTACAAGGG
2501 CCGCAACTTC CCCAACGACG GCCCCGTGAT GAAGAAGACC ATCACCGGCC
2551 TGCAGCCCAG CTTCGAGGTG GTGTACATGA ACGACGGCGT GCTGGTGGGC
2601 CAGGTGATCC TGGTGTACCG CCTGAACAGC GGCAAGTTCT ACAGCTGCCA
2651 CATGCGCACC CTGATGAAGA GCAAGGGCGT GGTGAAGGAC TTCCCCGAGT
2701 ACCACTTCAT CCAGCACCGC CTGGAGAAGA CCTACGTGGA GGACGGCGGC
2751 TTCGTGGAGC AGCACGAGAC CGCCATCGCC CAGCTGACCA GCCTGGGCAA
2801 GCCCCTGGGC AGCCTGCACG AGTGGGTGTA ATAGGGTACC AGGTAAGTGT
2851 ACCCAATTCG CCCTATAGTG AGTCGTATTA GATCTACGGG TGGCATCCCT
2901 GTGACCCCTC CCCAGTGCCT CTCCTGGCCC TGGAAGTTGC CACTCCAGTG
2951 CCCACCAGCC TTGTCCTAAT AAAATTAAGT TGCATCATTT TGTCTGACTA
3001 GGTGTCCTTC TATAATATTA TGGGGTGGAG GGGGGTGGTA TGGAGCAAGG
3051 GGCAAGTTGG GAAGACAACC TGTAGGGCCT GCGGGGTCTA TTGGGAACCA
3101 AGCTGGAGTG CAGTGGCACA ATCTTGGCTC ACTGCAATCT CCGCCTCCTG
3151 GGTTCAAGCG ATTCTCCTGC CTCAGCCTCC CGAGTTGTTG GGATTCCAGG
3201 CATGCATGAC CAGGCTCAGC TAATTTTTGT TTTTTTGGTA GAGACGGGGT
3251 TTCACCATAT TGGCCAGGCT GGTCTCCAAC TCCTAATCTC AGGTGATCTA
3301 CCCACCTTGG CCTCCCAAAT TGCTGGGATT ACAGGCGTGA ACCACTGCTC
3351 CCTTCCCTGT CCTTCTGATT TTGTAGGTAA CCACGTGCGG ACCGAGCGGC
3401 CGCAGGAACC CCTAGTGATG GAGTTGGCCA CTCCCTCTCT GCGCGCTCGC
3451 TCGCTCACTG AGGCCGGGCG ACCAAAGGTC GCCCGACGCC CGGGCTTTGC
3501 CCGGGCGGCC TCAGTGAGCG AGCGAGCGCG CAGCTGCCTG CAGGGGCGCC
3551 TGATGCGGTA TTTTCTCCTT ACGCATCTGT GCGGTATTTC ACACCGCATA
3601 CGTCAAAGCA ACCATAGTAC GCGCCCTGTA GCGGCGCATT AAGCGCGGCG
3651 GGTGTGGTGG TTACGCGCAG CGTGACCGCT ACACTTGCCA GCGCCCTAGC
3701 GCCCGCTCCT TTCGCTTTCT TCCCTTCCTTT CTCGCCACGT TCGCCGGCT
3751 TTCCCCGTCA AGCTCTAAAT CGGGGGCTCC CTTTAGGGTT CCGATTTAGT
3801 GCTTTACGGC ACCTCGACCC CAAAAAACTT GATTTGGGTG ATGGTTCACG
3851 TAGTGGGCCA TCGCCCTGAT AGACGGTTTT TCGCCCTTTG ACGTTGGAGT
3901 CCACGTTCTT TAATAGTGGA CTCTTGTTCC AAACTGGAAC AACACTCAAC
3951 CCTATCTCGG GCTATTCTTT TGATTTATAA GGGATTTTGC CGATTTCGGC
4001 CTATTGGTTA AAAAATGAGC TGATTTAACA AAAATTTAAC GCGAATTTTA
4051 ACAAAATATT AACGTTTACA ATTTTATGGT GCACTCTCAG TACAATCTGC
4101 TCTGATGCCG CATAGTTAAG CCAGCCCCGA CACCCGCCAA CACCCGCTGA
4151 CGCGCCCTGA CGGGCTTGTC TGCTCCCGGC ATCCGCTTAC AGACAAGCTG
4201 TGACCGTCTC CGGGAGCTGC ATGTGTCAGA GGTTTTCACC GTCATCACCG
4251 AAACGCGCGA GACGAAAGGG CCTCGTGATA CGCCTATTTT TATAGGTTAA
4301 TGTCATGATA ATAATGGTTT CTTAGACGTC AGGTGGCACT TTTCGGGGAA
4351 ATGTGCGCGG AACCCCTATT TGTTTATTTT TCTAAATACA TTCAAATATG
4401 TATCCGCTCA TGAGACAATA ACCCTGATAA ATGCTTCAAT AATATTGAAA
4451 AAGGAAGAGT ATGAGTATTC AACATTTCCG TGTCGCCCTT ATTCCCTTTT
4501 TTGCGGCATT TTGCCTTCCT GTTTTTGCTC ACCCAGAAAC GCTGGTGAAA
4551 GTAAAAGATG CTGAAGATCA GTTGGGTGCA CGAGTGGGTT ACATCGAACT
4601 GGATCTCAAC AGCGGTAAGA TCCTTGAGAG TTTTCGCCCC GAAGAACGTT
4651 TTCCAATGAT GAGCACTTTT AAAGTTCTGC TATGTGGCGC GGTATTATCC
4701 CGTATTGACG CCGGGCAAGA GCAACTCGGT CGCCGCATAC ACTATTCTCA
4751 GAATGACTTG GTTGAGTACT CACCAGTCAC AGAAAAGCAT CTTACGGATG
4801 GCATGACAGT AAGAGAATTA TGCAGTGCTG CCATAACCAT GAGTGATAAC
4851 ACTGCGGCCA ACTTACTTCT GACAACGATC GGAGGACCGA AGGAGCTAAC
4901 CGCTTTTTTG CACAACATGG GGGATCATGT AACTCGCCTT GATCGTTGGG
4951 AACCGGAGCT GAATGAAGCC ATACCAAACG ACGAGCGTGA CACCACGATG
5001 CCTGTAGCAA TGGCAACAAC GTTGCGCAAA CTATTAACTG GCGAACTACT
5051 TACTCTAGCT TCCCGGCAAC AATTAATAGA CTGGATGGAG GCGGATAAAG
5101 TTGCAGGACC ACTTCTGCGC TCGGCCCTTC CGGCTGGCTG GTTTATTGCT
5151 GATAAATCTG GAGCCGGTGA GCGTGGGTCT CGCGGTATCA TTGCAGCACT
5201 GGGGCCAGAT GGTAAGCCCT CCCGTATCGT AGTTATCTAC ACGACGGGGA
5251 GTCAGGCAAC TATGGATGAA CGAAATAGAC AGATCGCTGA GATAGGTGCC
5301 TCACTGATTA AGCATTGGTA ACTGTCAGAC CAAGTTTACT CATATATACT
5351 TTAGATTGAT TTAAAACTTC ATTTTTAATT TAAAAGGATC TAGGTGAAGA
5401 TCCTTTTTGA TAATCTCATG ACCAAAATCC CTTAACGTGA GTTTTCGTTC
5451 CACTGAGCGT CAGACCCCGT AGAAAAGATC AAAGGATCTT CTTGAGATCC
5501 TTTTTTTCTG CGCGTAATCT GCTGCTTGCA AACAAAAAAA CCACCGCTAC
5551 CAGCGGTGGT TTGTTTGCCG GATCAAGAGC TACCAACTCT TTTTCCGAAG
5601 GTAACTGGCT TCAGCAGAGC GCAGATACCA AATACTGTCC TTCTAGTGTA
5651 GCCGTAGTTA GGCCACCACT TCAAGAACTC TGTAGCACCG CCTACATACC
5701 TCGCTCTGCT AATCCTGTTA CCAGTGGCTG CTGCCAGTGG CGATAAGTCG
5751 TGTCTTACCG GGTTGGACTC AAGACGATAG TTACCGGATA AGGCGCAGCG
5801 GTCGGGCTGA ACGGGGGGTT CGTGCACACA GCCCAGCTTG GAGCGAACGA
5851 CCTACACCGA ACTGAGATAC CTACAGCGTG AGCTATGAGA AAGCGCCACG
5901 CTTCCCGAAG GGAGAAAGGC GGACAGGTAT CCGGTAAGCG GCAGGGTCGG
5951 AACAGGAGAG CGCACGAGGG AGCTTCCAGG GGGAAACGCC TGGTATCTTT
6001 ATAGTCCTGT CGGGTTTCGC CACCTCTGAC TTGAGCGTCG ATTTTTGTGA
6051 TGCTCGTCAG GGGGGCGGAG CCTATGGAAA AACGCCAGCA ACGCGGCCTT
6101 TTTACGGTTC CTGGCCTTTT GCTGGCCTTT TGCTCACATG Tagcattggt
关联产品
pHelper质粒DNA
ELISA试剂盒
人ELISA试剂盒| 大鼠ELISA试剂盒| 小鼠ELISA试剂盒| 牛ELISA试剂盒| 猪ELISA试剂盒| 鸡ELISA试剂盒| 犬ELISA试剂盒| 猫ELISA试剂盒| 马ELISA试剂盒| 植物ELISA试剂盒| 山羊ELISA试剂盒| 绵羊ELISA试剂盒| 鸭ELISA试剂盒| 兔ELISA试剂盒| 鱼ELISA试剂盒| 豚鼠ELISA试剂盒| 鹅ELISA试剂盒| 药物残留ELISA试剂盒| 兽药残留快速检测卡| 毒素类ELISA试剂盒| 其他ELISA试剂盒| Human ELISA Kit| Rat ELISA Kit| Mouse ELISA Kit| Procine ELISA Kit| Rabbit ELISA Kit| Guinea ELISA Kit| Chicken ELISA Kit| Sheep ELISA Kit| Canine ELISA Kit| 其它ELISA试剂盒|
高敏ELISA试剂盒
高敏人Elisa试剂盒| 高敏小鼠Elisa试剂盒| 高敏大鼠Elisa试剂盒| 高敏豚鼠Elisa试剂盒| 高敏裸鼠Elisa试剂盒| 高敏仓鼠Elisa试剂盒| 高敏沙鼠Elisa试剂盒| 高敏鸭Elisa试剂盒| 高敏鹅Elisa试剂盒| 高敏猴Elisa试剂盒| 高敏兔Elisa试剂盒| 高敏马Elisa试剂盒| 高敏绵羊Elisa试剂盒| 高敏山羊Elisa试剂盒| 高敏犬Elisa试剂盒| 高敏牛Elisa试剂盒| 高敏鱼Elisa试剂盒|
技术服务
微量法检测系列| 细胞生物学| 分子生物学| 物质分析| 病理学| 免疫学| 病毒包装| 动物造模| 蛋白表达| 抗体制备| 文库构建和筛选| RACE实验| 杂交实验| HPLC法检测项目| 气相色谱法检测项目|
染色试剂&糖类
染色液| 固定液| 染料| 褐藻寡糖系列| 壳寡糖系列| 琼胶寡糖系列| 卡拉胶寡糖系列| 木寡糖系列| 棉籽半乳寡糖系列| 不饱和硫酸软骨素二糖系列| 透明质酸寡糖系列| 麦芽寡糖系列| 海洋寡糖原料类|
荧光定量比色法试剂盒
细胞技术类产品| 生化试剂盒| 分子技术类产品| 蛋白化学技术类产品| 免疫抗体技术类产品| 医学技术类产品| 病理技术类产品| 生物化学技术类产品| 模式生物技术类产品| 微生物技术类产品| 植物技术类产品| 载体技术类产品| 毒理技术类产品| 营养技术类产品| 平台技术类产品| 其他相关产品|
生化试剂
蛋白质类| 氨基酸&多肽&蛋白质| 抗生素(生化试剂)| 酶&辅酶&抑制剂| 动植物激素| 碳水化合物及衍生物| 色素类| 维生素| 分离材料及耗材| 表面活性剂| 缓冲溶剂| 其他化学试剂| 碱基&核酸及其衍生物| 酸&盐&胺| 常规生化试剂|
细胞生物学
细胞生长因子| 细胞辅助试剂| 细胞培养| 细胞检测试剂| 细胞系(株)| 细胞分离与消化| 细胞染色与探针| 细胞转染| 鲎试剂| 免疫细胞及干细胞| 其他原代细胞| 小鼠原代细胞| 大鼠原代细胞| 人源原代细胞| 其他细胞系| 小鼠细胞系| 大鼠细胞系| 人源细胞系|
分析对照品、标准品
农药标准物质| 天然药物系列单体| 英国LGC标准品| 美国药典标准品| 中检所标准品| 中药对照品| 对照药材| 标准溶液| 进口标准品| 分析对照品| 衍生化试剂| 离子对试剂|
代理品牌
Life试剂| Amresco试剂| Sigma试剂| R&D试剂| Merck试剂| Novus试剂| Lifespan试剂| eBioscience| Pepro Tech| Gene Tex| Cayman| ENZO| Serotec| Active Motif| InvivoGen| ProZyme| Vetorlabs| Mirus| Fitzgerald| Biovendor| BioVision| 罗恩试剂| 美森细胞|





