CAT#:JW-1-287
低温运输,-20℃保存
产品及特点
本产品为 pAc5. 1V5-His B 质粒 DNA ,是具有 P-AC5 (Actin 5C)启动子的果蝇 表达载体,可用于以果蝇细胞为宿主的重组蛋白的高水平瞬时表达。pAc5. 1V5-His B 质粒 DNA 具有多克隆位点 , 方便用户在不同酶切位点插入所选基因进行研究或表达。
本质粒携带 Amp 抗性基因 。其图谱如下: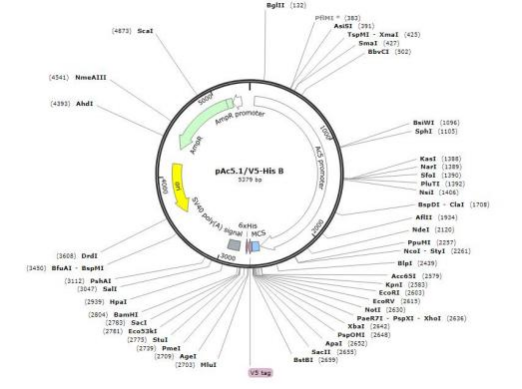
规格及成分 本产品使用塑料袋包装
成分 编号 规格 包装
pAc5. 1V5-His B 质粒 DNA 溶液(浓度见标签) 1-287 2 μg 0.5 mL 本色管
使用手册 1-287sc 1 份 无
运输及保存 低温运输 ,-20℃保存 ,有效期两年。
使用方法 pAc5. 1V5-His B 质粒 DNA 溶液可直接用于酶切克隆。也可以取少量,按常规方法进行细菌转化 ,制备更多的质粒 DNA 进行各种后续实验。
DNA 序列
1 CTTCAAGGAA TTAATTCTAT ATTCTAAAAA CACAAATGAT ACTTCTAAAA 50
51 AAAATCATGA ATGGCATCAA CTCTGAATCA AATCTTTGCA GATGCACCTA 100
101 CTTCTCATTT CCACTGTCAC ATCATTTTTC CAGATCTCGC TGCCTGTTAT 150
151 GTGGCCCACA AACCAAGACA CGTTTTATGG CCATTAAAGC TGGCTGATCG+ 200
201 TCGCCAAACA CCAAATACAT ATCAATATGT ACATTCGAGA AAGAAGCGAT 250
251 CAAAGAAGCG TCTTCGGGCG AGTAGGAGAA TGCGGAGGAG AAGGAGAACG 300
301 AGCTGATCTA GTATCTCTCC ACAATCCAAT GCCAACTGAC CAACTGGCCA 350
351 TATTCGGAGC AATTTGAAGC CAATTTCCAT CGCCTGGCGA TCGCTCCATT 400
401 CTTGGCTATA TGTTTTTCAC CGTTCCCGGG GCCATTTTCA AAGACTCGTC 450
451 GGTAAGATAA GATTGTGTCA CTCGCTGTCT CTCTTCATTT GTCGAAGAAT 500
501 GCTGAGGAAT TTCGCGATGA CGTCGGCGAG TATTTTGAAG AATGAGAATA 550
551 ATTTGTATTT ATACGAAAAT CAGTTAGTGG AATTTTCTAC AAAAACATGT 600
601 TATCTATAGA TAATTTTGTT GCAAAATATG TTGACTATGA CAAAGATTGT 650
651 ATGTATATAC CTTTAATGTA TTCTCATTTT CTTATGTATT TATAATGGCA 700
701 ATGATGATAC TGATGATATT TTAAGATGAT GCCAGACCAC AGGCTGATTT 750
751 CTGCGTCTTT TGCCGAACGC AGTGCATGTG CGGTTGTTGT TTTTTGGAAT 800
801 AGTTTCAATT TTCGGACTGT CCGCTTTGAT TTCAGTTTCT TGGCTTATTC 850
851 AAAAAGCAAA GTAAAGCCAA AAAAGCGAGA TGGCAATACC AAATGCGGCA 900
901 AAACGGTAGT GGAAGGAAAG GGGTGCGGGG CAGCGGAAGG AAGGGTGGGG 950
951 CGGGGCGTGG CGGGGTCTGT GGCTGGGCGC GACGTCACCG ACGTTGGAGC 1000
1001 CACTCCTTTG ACCATGTGTG CGTGTGTGTA TTATTCGTGT CTCGCCACTC 1050
1051 GCCGGTTGTT TTTTTCTTTT TATCTCGCTC TCTCTAGCGC CATCTCGTAC 1100
1101 GCATGCTCAA CGCACCGCAT GTTGCCGTGT CCTTTATGCG TCATTTTGGC 1150
1151 TCGAAATAGG CAATTATTTA AACAAAGATT AGTCAACGAA AACGCTAAAA 1200
1201 TAAATAAGTC TACAATATGG TTACTTATTG CCATGTGTGT GCAGCCAACG 1250
1251 ATAGCAACAA AAGCAACAAC ACAGTGGCTT TCCCTCTTTC ACTTTTTGTT 1300
1301 TGCAAGCGCG TGCGAGCAAG ACGGCACGAC CGGCAAACGC AATTACGCTG 1350
1351 ACAAAGAGCA GACGAAGTTT TGGCCGAAAA ACATCAAGGC GCCTGATACG 1400
1401 AATGCATTTG CAATAACAAT TGCGATATTT AATATTGTTT ATGAAGCTGT 1450
1451 TTGACTTCAA AACACACAAA AAAAAAAATA AAACAAATTA TTTGAAAGAG 1500
1501 AATTAGGAAT CGGACAGCTT ATCGTTACGG GCTAACAGCA CACCGAGACG 1550
1551 AAATAGCTTA CCTGACGTCA CAGCCTCTGG AAGAACTGCC GCCAAGCAGA 1600
1601 GAGAGAGAGA AAAAGAGGGA GAGCAGCTTA GACCGCATGT GCTTGTGTGT 1650
1651 GAGGCGTCTC TCTCTTCGTC TCCTGTTTGC GCAAACGCAT AGACTGCACT 1700
1701 GAGAAAATCG ATTACCTATT TTTTATGAAT GAATATTTGC ACTATTACTA 1750
1751 TTCAAAACTA TTAAGATAGC AATCACATTC AATAGCCAAA TACTATACCA 1800
1801 CCTGAGCGAT GCAACGAAAT GATCAATTTG AGCAAAAATG CTGCATATTT 1850
1851 AGGACGGCAT CATTATAGAA ATGCTTCTTG CTGTGTACTT TTCTCTCGTC 1900
1901 TGGCAGCTGT TTCGCCGTTA TTGTTAAAAC CGGCTTAAGT TAGGTGTGTT 1950
1951 TTCTACGACT AGTGATGCCC CTACTAGAAG ATGTGTGTTG CACAAATGTC 2000
2001 CCTGAATAAC CAATTTGAAG TGCAGATAGC AGTAAACGTA AGCTAATATG 2050
2051 AATATTATTT AACTGTAATG TTTTAATATC GCTGGACATT ACTAATAAAC 2100
2101 CCACTATAAA CACATGTACA TATGTATGTT TTGGCATACA ATGAGTAGTT 2150
2151 GGGGAAAAAA TGTGTAAAAG CACCGTGACC ATCACAGCAT AAAGATAACC 2200
2201 AGCTGAAGTA TCGAATATGA GTAACCCCCA AATTGAATCA CATGCCGCAA 2250
2251 CTGATAGGAC CCATGGAAGT ACACTCTTCA TGGCGATATA CAAGACACAC 2300
2301 ACAAGCACGA ACACCCAGTT GCGGAGGAAA TTCTCCGTAA ATGAAAACCC 2350
2351 AATCGGCGAA CAATTCATAC CCATATATGG TAAAAGTTTT GAACGCGACT 2400
2401 TGAGAGCGGA GAGCATTGCG GCTGATAAGG TTTTAGCGCT AAGCGGGCTT 2450
2451 TATAAAACGG GCTGCGGGAC CAGTTTTCAT ATCACTACCG TTTGAGTTCT 2500
2501 TGTGCTGTGT GGATACTCCT CCCGACACAA AGCCGCTCCA TCAGCCAGCA 2550
2551 GTCGTCTAAT CCAGAGACCC CGGATCGGGG TACCTACTAG TCCAGTGTGG 2600
2601 TGGAATTCTG CAGATATCCA GCACAGTGGC GGCCGCTCGA GTCTAGAGGG 2650
2651 CCCGCGGTTC GAAGGTAAGC CTATCCCTAA CCCTCTCCTC GGTCTCGATT 2700
2701 CTACGCGTAC CGGTCATCAT CACCATCACC ATTGAGTTTA AACCCGCTGA 2750
2751 TCAGCCTCGA CTGTGCCTTC TAAGGCCTGA GCTCGCTGAT CAGCCTCGAT 2800
2801 CGAGGATCCA GACATGATAA GATACATTGA TGAGTTTGGA CAAACCACAA 2850
2851 CTAGAATGCA GTGAAAAAAA TGCTTTATTT GTGAAATTTG TGATGCTATT 2900
2901 GCTTTATTTG TAACCATTAT AAGCTGCAAT AAACAAGTTA ACAACAACAA 2950
2951 TTGCATTCAT TTTATGTTTC AGGTTCAGGG GGAGGTGTGG GAGGTTTTTT 3000
3001 AAAGCAAGTA AAACCTCTAC AAATGTGGTA TGGCTGATTA TGATCAGTCG 3050
3051 ACCGATGCCC TTGAGAGCCT TCAACCCAGT CAGCTCCTTC CGGTGGGCGC 3100
3101 GGGGCATGAC TATCGTCGCC GCACTTATGA CTGTCTTCTT TATCATGCAA 3150
3151 CTCGTAGGAC AGGTGCCGGC AGCGCTCTGG GTCATTTTCG GCGAGGACCG 3200
3201 CTTTCGCTGG AGCGCGACGA TGATCGGCCT GTCGCTTGCG GTATTCGGAA 3250
3251 TCTTGCACGC CCTCGCTCAA GCCTTCGTCA CTGGTCCCGC CACCAAACGT 3300
3301 TTCGGCGAGA AGCAGGCCAT TATCGCCGGC ATGGCGGCCG ACGCGCTGGG 3350
3351 CTACGTCTTG CTGGCGTTCG CGACGCGAGG CTGGATGGCC TTCCCCATTA 3400
3401 TGATTCTTCT CGCTTCCGGC GGCATCGGGA TGCCCGCGTT GCAGGCCATG 3450
3451 CTGTCCAGGC AGGTAGATGA CGACCATCAG GGACAGCTTC AAGGATCGCT 3500
3501 CGCGGCTCTT ACCAGCCAGC AAAAGGCCAG GAACCGTAAA AAGGCCGCGT 3550
3551 TGCTGGCGTT TTTCCATAGG CTCCGCCCCC CTGACGAGCA TCACAAAAAT 3600
3601 CGACGCTCAA GTCAGAGGTG GCGAAACCCG ACAGGACTAT AAAGATACCA 3650
3651 GGCGTTTCCC CCTGGAAGCT CCCTCGTGCG CTCTCCTGTT CCGACCCTGC 3700
3701 CGCTTACCGG ATACCTGTCC GCCTTTCTCC CTTCGGGAAG CGTGGCGCTT 3750
3751 TCTCAATGCT CACGCTGTAG GTATCTCAGT TCGGTGTAGG TCGTTCGCTC 3800
3801 CAAGCTGGGC TGTGTGCACG AACCCCCCGT TCAGCCCGAC CGCTGCGCCT 3850
3851 TATCCGGTAA CTATCGTCTT GAGTCCAACC CGGTAAGACA CGACTTATCG 3900
3901 CCACTGGCAG CAGCCACTGG TAACAGGATT AGCAGAGCGA GGTATGTAGG 3950
3951 CGGTGCTACA GAGTTCTTGA AGTGGTGGCC TAACTACGGC TACACTAGAA 4000
4001 GGACAGTATT TGGTATCTGC GCTCTGCTGA AGCCAGTTAC CTTCGGAAAA 4050
4051 AGAGTTGGTA GCTCTTGATC CGGCAAACAA ACCACCGCTG GTAGCGGTGG 4100
4101 TTTTTTTGTT TGCAAGCAGC AGATTACGCG CAGAAAAAAA GGATCTCAAG 4150
4151 AAGATCCTTT GATCTTTTCT ACGGGGTCTG ACGCTCAGTG GAACGAAAAC 4200
4201 TCACGTTAAG GGATTTTGGT CATGAGATTA TCAAAAAGGA TCTTCACCTA 4250
4251 GATCCTTTTA AATTAAAAAT GAAGTTTTAA ATCAATCTAA AGTATATATG 4300
4301 AGTAAACTTG GTCTGACAGT TACCAATGCT TAATCAGTGA GGCACCTATC 4350
4351 TCAGCGATCT GTCTATTTCG TTCATCCATA GTTGCCTGAC TCCCCGTCGT 4400
4401 GTAGATAACT ACGATACGGG AGGGCTTACC ATCTGGCCCC AGTGCTGCAA 4450
4451 TGATACCGCG AGACCCACGC TCACCGGCTC CAGATTTATC AGCAATAAAC 4500
4501 CAGCCAGCCG GAAGGGCCGA GCGCAGAAGT GGTCCTGCAA CTTTATCCGC 4550
4551 CTCCATCCAG TCTATTAATT GTTGCCGGGA AGCTAGAGTA AGTAGTTCGC 4600
4601 CAGTTAATAG TTTGCGCAAC GTTGTTGCCA TTGCTGCAGG CATCGTGGTG 4650
4651 TCACGCTCGT CGTTTGGTAT GGCTTCATTC AGCTCCGGTT CCCAACGATC 4700
4701 AAGGCGAGTT ACATGATCCC CCATGTTGTG CAAAAAAGCG GTTAGCTCCT 4750
4751 TCGGTCCTCC GATCGTTGTC AGAAGTAAGT TGGCCGCAGT GTTATCACTC 4800
4801 ATGGTTATGG CAGCACTGCA TAATTCTCTT ACTGTCATGC CATCCGTAAG 4850
4851 ATGCTTTTCT GTGACTGGTG AGTACTCAAC CAAGTCATTC TGAGAATAGT 4900
4901 GTATGCGGCG ACCGAGTTGC TCTTGCCCGG CGTCAACACG GGATAATACC 4950
4951 GCGCCACATA GCAGAACTTT AAAAGTGCTC ATCATTGGAA AACGTTCTTC 5000
5001 GGGGCGAAAA CTCTCAAGGA TCTTACCGCT GTTGAGATCC AGTTCGATGT 5050
5051 AACCCACTCG TGCACCCAAC TGATCTTCAG CATCTTTTAC TTTCACCAGC 5100
5101 GTTTCTGGGT GAGCAAAAAC AGGAAGGCAA AATGCCGCAA AAAAGGGAAT 5150
5151 AAGGGCGACA CGGAAATGTT GAATACTCAT ACTCTTCCTT TTTCAATATT 5200
5201 ATTGAAGCAT TTATCAGGGT TATTGTCTCA TGAGCGGATA CATATTTGAA 5250
5251 TGTATTTAGA AAAATAAACA AATAGGGGTT CCGCGCACAT TTCCCCGAAA 5300
5301 AGTGCCACCT GACGTCTAAG AAACCATTAT TATCATGACA TTAACCTATA 5350
5351 AAAATAGGCG TATCACGAGG CCCTTTCGT 5379
关联产品 大肠杆菌 DH5a感受态细胞





